abstract
- 论文地址:https://arxiv.org/abs/1703.06211
- 代码:https://github.com/msracver/Deformable-ConvNets
- 论文中提出了2个模块,用于提升CNN的
transformation modeling capability,称之为deformable convolution与deformable roi pooling,这都是希望能够增强CNN的空间采样能力,使得网络可以关注feature map中更加重要的部分。 - 介绍的新的模块可以很容易地被用于其他的网络结构中,也可以使用BP进行学习。
- 论文中第一次展示了:学习CNN中的
dense spatial transformation对于复杂的视觉任务是很有帮助的。
introduction
- 物体识别任务中,主要的挑战就是怎么去解决由于
scale、pose、viewpoint、part deformation等原因导致的识别困难的问题。有2种主要的方法:- 使用这些变化,对训练数据进行增强,使得网路对这些变换更加鲁棒。但是使用数据增强的方法都是使用已知的变换进行的,因此如果在新的数据集上出现了其他的变换,则模型无法处理这种情况。
- 使用具有变换不变性的特征与算法,比如说SIFT或者基于滑动窗口的检测算法等。但是这种人工设计的特征和算法对于复杂任务也是非常困难的。
- CNN的特征提取主要是基于卷积核实现,传统的卷积核有比较明显的局限性,因为他只能采集到固定的局部信息,而且卷积核的形状都是固定的,因此难以适用于形状变化较大的物体。此外,在high-level layer中,所有kernel的respective field都是相同的,这显然不符合不同物体的规律。
- 本文提出了2个新的模块,用于解决上述问题,下图是卷积核在卷积的过程中使用不同的采样方法的可视化。

- 本文的方法与之前的
high level spirit with spatial transform networks以及deformable part models都比较相似,都是内部变换参数,同时这种变换完全是从数据中学习得到的,无需手动设计特征。但是本文提出的方法很轻便,易于扩展到其他网络结构上,同时可以直接实现端到端的训练与预测。
Deformable Convolutional Networks
- feature map和CNN都是3D的(xyc),本文中
deformable convolution and roipooling都设置为2D空间上的操作。即同一个网络层中所有通道上的deformation的。
Deformable Convolution
- 传统的CNN中,假设卷积的grid $\Re$为
$$\Re = {(-1,-1),(-1,0),…,(1,1)}$$
假设$\Re$集合中的元素个数为其中$N$。卷积的计算方式为
$$y({p_0}) = \sum\limits_{p_n \in \Re } {w(p_n) \cdot x(p_0 + p_n)}$$
deformable convolution中,每个位置都有一个微小的变化,卷积可以表示为
$$y({p_0}) = \sum\limits_{p_n \in \Re } {w(p_n) \cdot x(p_0 + p_n + \Delta p_n)}$$
其中$\Delta p_n$是微小的变化,因此在计算该位置的输入时,使用双线性插值进行计算。deformable convolution可视化如下。
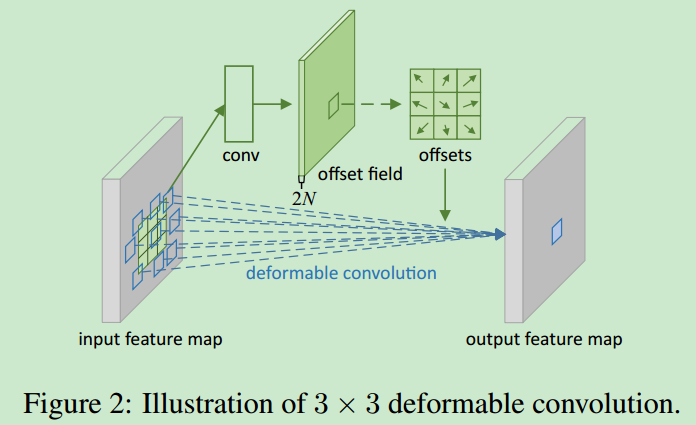
- 经过卷积的到的
offset map的通道数是$2N$个,size与原始的feature map size相同,这就可以保证在每个不同的位置进行卷积的时候,都有一个offset,因为每个offset都是由$\Delta x$与$\Delta y$组成的。
Deformable RoI Pooling
deformable roipooling与deformable PS roipooling可视化如下。
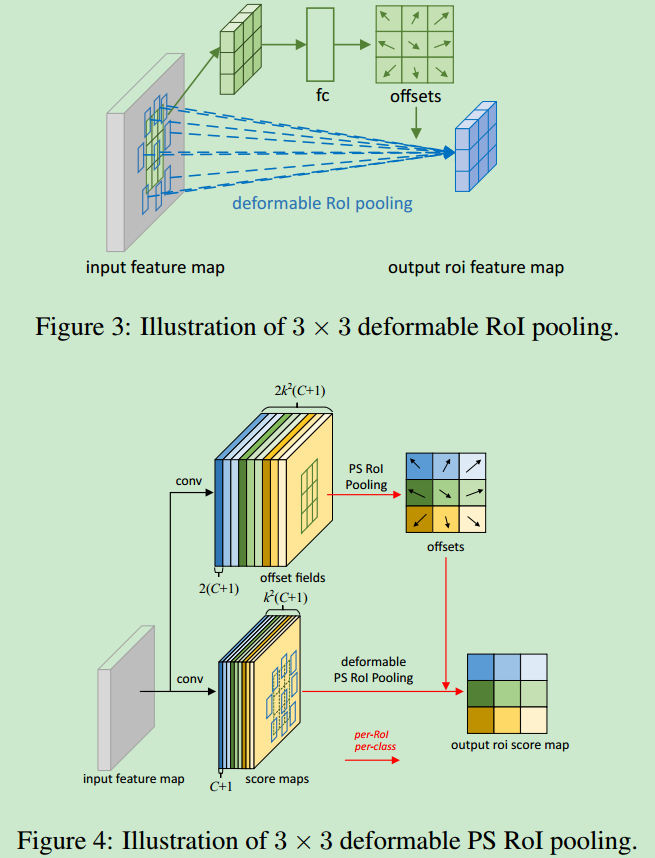
在deformable roipooling时,首先根据input feature map生成pooling feature msp,经过fc layer得到normalized offsets $\Delta \hat p_{i,j}$(每个pooling feature map上的点都生成这样一个normalized offset),之后再转化成offset,使用下面的公式进行转换(乘以roi的宽高以及一个超参数$\gamma$),主要是为了避免roi size对offset的影响。
$$\Delta p_{i,j} = \gamma \cdot \Delta \hat p_{i,j} \circ (w,h)$$
在deformable PS roipooling中,使用conv生成$k \times k \times 2(C+1)$个channel的offset。
Deformable ConvNets
- 其实与之前的网络结构都是相似的,只是多了需要学习offset layer的参数,这些参数在初始时刻全被设置为0。
- 本文中,在feature extraction backbone的最后几层加了deformable convolution,最后实验发现层数为3时,效果较好。
- 在具体的任务上,作者针对分割和检测任务都做了实验
Understanding Deformable ConvNets
- deformable convolution的感受野可视化如下所示
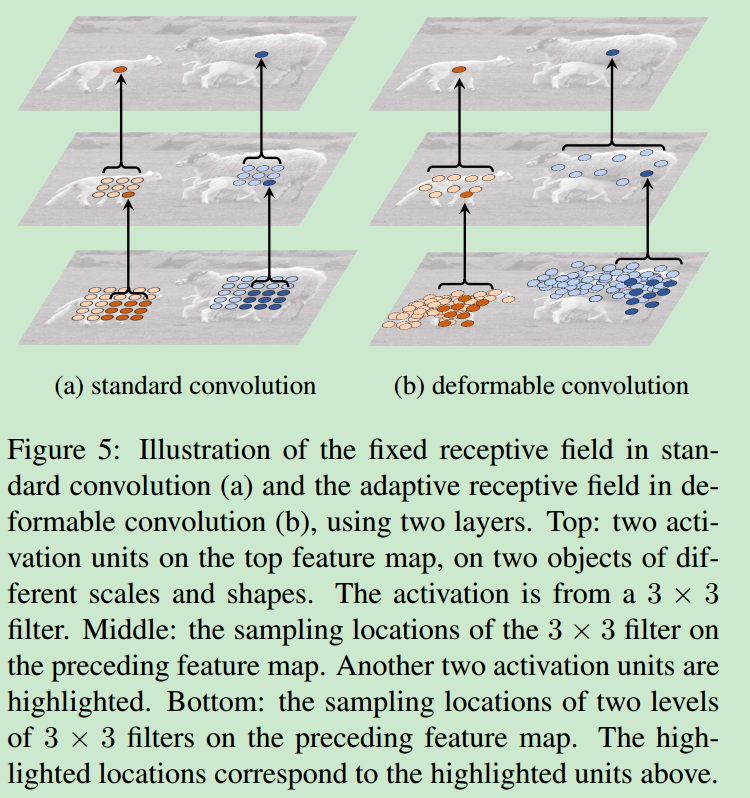
可以看出,deformable convolution的一大优势就是可以使用学习的方式,对convolution kernel的形状进行修改,从而使得网络对物体变形、尺寸变化等问题能够有更好的性能。在实际的任务中,deformable convnets学习到的采样点如下所示。

- 论文中提到了一些当前针对目标检测的比较流行的方案,有兴趣的话读者可以作为综述看一下。
experiments
deformable convolution在语义分割与目标检测任务中的性能表现如下。
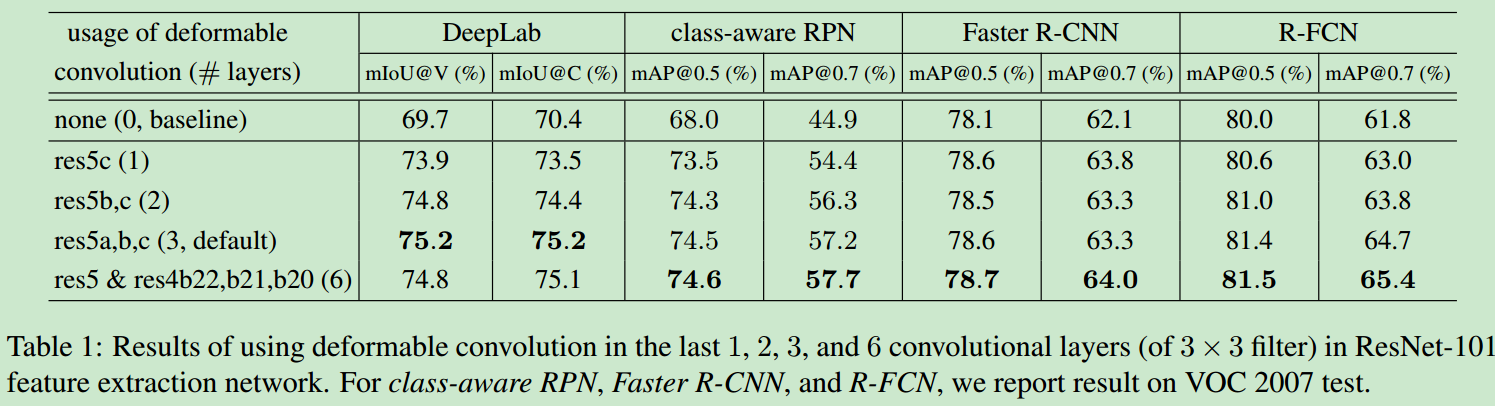
Evaluation of Deformable Convolution
- 定义一种度量方式,称为
effective dilation for a deformable convolution filter,表示所有filter中两个相邻采样点的距离的平均值。这可以大致表示filter的respective field size。结果如下
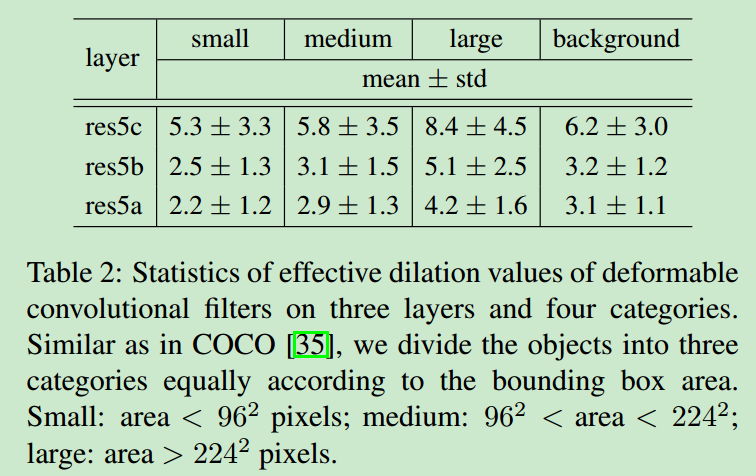
可以看出deformable filter的感受野大小与物体的大小是相关的,这也说明了论文中deformable convolution的有效性。
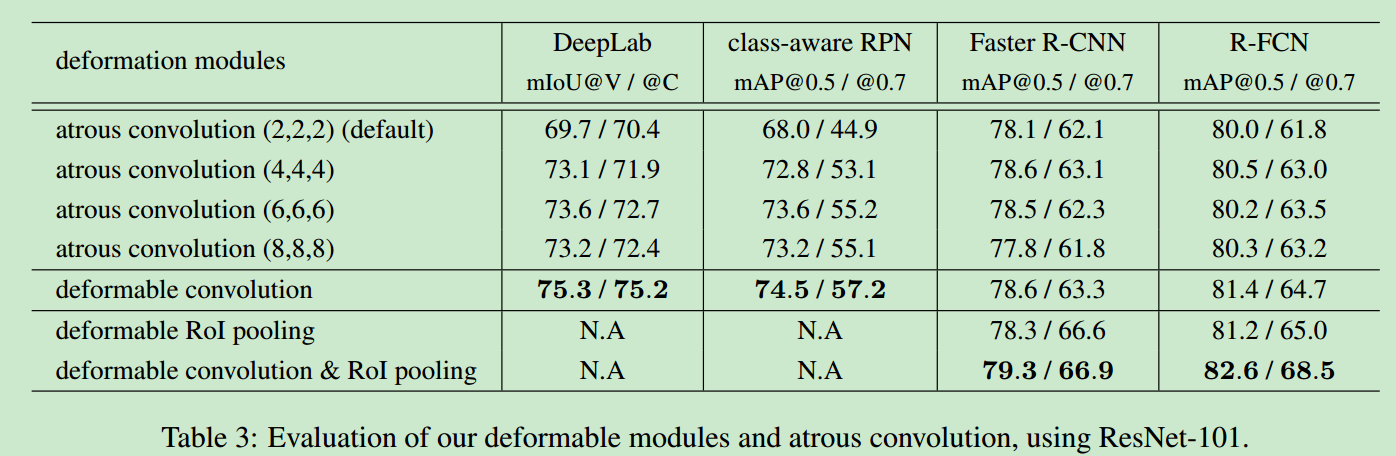
Evaluation of Deformable RoI Pooling
- roi pooling在fasterRCNN中应用比较多,论文基于fasterRCNN的
roipooling与RFCN的PS roipooling都做了实验,改进结果对比如下所示。
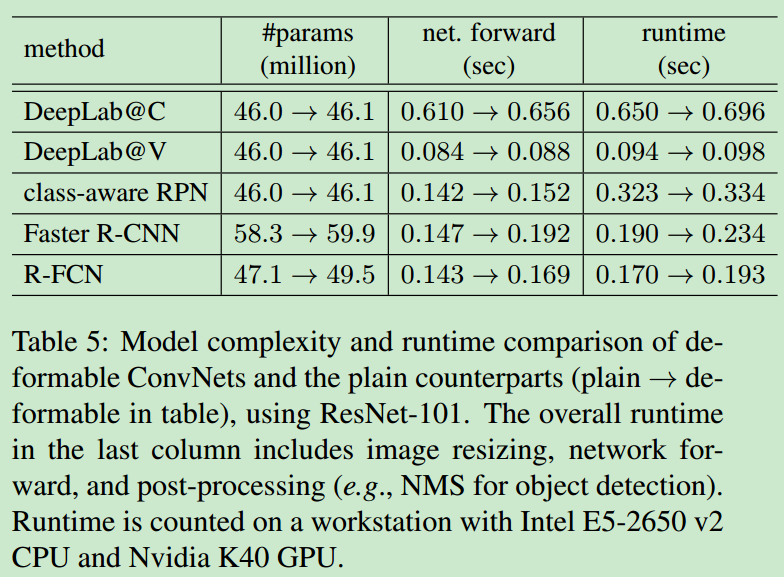
model complexity and runtime
- 改进后模型的参数运行时间对比如下所示,可以看出在几乎不增加参数量与运行时间的情况下,论文的方法带来了较大的性能提升。
conclusion
- 论文竟然没有conclusion,震惊。